
Bei Metagoofil handelt es sich um ein Tool zum Sammeln von Metadaten aus öffentlichen Dokumenten eines Zielunternehmens. Dabei zielt das Tool auf Formate, in denen häufig Meta-Informationen zu finden sind wie pdf, doc, xls, ppt, docx, pptx oder xlsx. Im Folgenden zeigen wir, woher man Metagoofil bezieht und wie man es einsetzt.
Wie funktioniert Metagoofil?
Das Tool sucht zunächst über Google nach relevanten Dateien im Zusammenhang mit dem Zielunternehmen und speichert diese lokal ab. Anschließend extrahiert es die Metadaten mit Hilfe verschiedener Bibliotheken wie Hachoir oder PdfMiner. Aus den gewonnenen Informationen generiert Metagoofil dann einen Bericht, welcher zahlreiche Informationen wie etwa Benutzernamen, Softwareversionen und Computernamen enthält. Diese Informationen sollen den Penetrationstester in der Informationsbeschaffungsphase seines Penetrationstests unterstützen.
Woher kann man Metagoofil beziehen?
Beziehen kann man Metagoofil über folgende Befehle:
git clone https://github.com/opsdisk/metagoofil
cd metagoofil
pip3 install -r requirements.txt
Wie führt man Metagoofil aus?
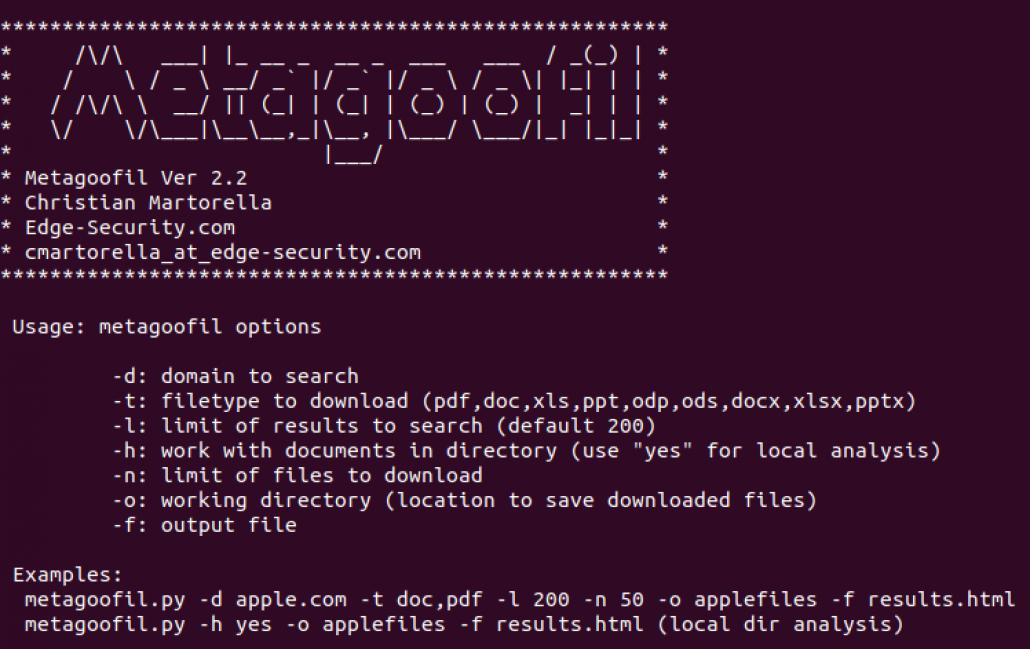
Ausführen kann man Metagoofil wie folgt:
python3 metagoofil.py -h
Es sollte dann folgende Hilfe erscheinen:
usage: metagoofil.py [-h] -d DOMAIN [-e DELAY] [-f] [-i URL_TIMEOUT] [-l SEARCH_MAX] [-n DOWNLOAD_FILE_LIMIT]
[-o SAVE_DIRECTORY] [-r NUMBER_OF_THREADS] -t FILE_TYPES [-u [USER_AGENT]] [-w]
Metagoofil - Search and download specific filetypes
optional arguments:
-h, --help show this help message and exit
-d DOMAIN Domain to search.
-e DELAY Delay (in seconds) between searches. If it's too small Google may block your IP, too big and your
searchmay take a while. Default: 30.0
-f Save the html links to html_links_<TIMESTAMP>.txt file.
-i URL_TIMEOUT Number of seconds to wait before timeout for unreachable/stale pages. Default: 15
-l SEARCH_MAX Maximum results to search. Default: 100
-n DOWNLOAD_FILE_LIMIT
Maximum number of files to download per filetype. Default: 100
-o SAVE_DIRECTORY Directory to save downloaded files. Default is current working directory, "."
-r NUMBER_OF_THREADS Number of downloader threads. Default: 8
-t FILE_TYPES file_types to download (pdf,doc,xls,ppt,odp,ods,docx,xlsx,pptx). To search all 17,576 three-letter
file extensions, type "ALL"
-u [USER_AGENT] User-Agent for file retrieval against -d domain.
no -u = "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
-u = Randomize User-Agent
-u "My custom user agent 2.0" = Your customized User-Agent
-w Download the files, instead of just viewing search results.
Parameter:
-h: Hilfe anzeigen
-d: Die zu scannende Domain
-e: Verzögerung (in Sekunden) zwischen den Anfragen. Standardmäßig: 30
-f: Speichert HTML-Links in der Datei html_links_<TIMESTAMP>.txt.
-i: Anzahl der Sekunden, die gewartet werden soll, bevor ein Timeout für nicht erreichbare Seiten erfolgt. Standardmäßig: 15
-l: Maximal Anzahl an Suchergebnissen (Standardmäßig 200)
-n: Maximale Anzahl an Downloads
-o: Verzeichnis, in das heruntergeladene Dateien abgelegt werden
-r: Anzahl der Downloader-Threads. Standardmäßig: 8
-t: Dateitypen, die heruntergeladen werden sollen (pdf,doc,xls,ppt,odp,ods,docx,xlsx,pptx)
-u: Der für die Anfragen zu verwendende User-Agent
-w: Dateien herunterladen, anstatt nur die Suchergebnisse anzuzeigen.
Beispiel-Aufruf:
python metagoofil.py -d whitehat.de -t all

